Introduction to Probability
Probability gives the information about how likely an event can occur. Digging into the terminology of the probability:
Trial or Experiment: The act that leads to a result with certain possibility.
Sample space: The set of all possible outcomes of an experiment.
Event: Non empty subset of sample space is known as event.
So, probability is the measure of how likely an event is when an experiment is conducted.
Basic probability calculation
As per the definition, if A is an event of an experiment and it contains n outcomes and S is the sample space then,
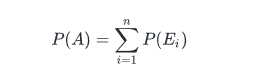
where E1……En are the outcomes in A. If all the outcomes of the experiment are equally likely then

Hence the value of probability is between 0 and 1. As the sample space is the whole possible set of outcomes, P(S)=1
Complement of A: Complement of an event A means not(A). Probability of complement event of A means the probability of all the outcomes in sample space other than the ones in A. Denoted by Ac and P(Ac)=1-P(A)
Union and Intersection: The probability of intersection of two events A and B is P(A∩B). When event A occurs in union with event B then the probability together is defined as P(A∪B)=P(A)+P(B)-P(A∩B) which is also known as the addition rule of probability.
Mutually exclusive: Any two events are mutually exclusive when they have non-overlapping outcomes i.e. if A and B are two mutually exclusive events then, P(A∩B) =0 . From the addition rule of probability P(A∪B)=P(A)+P(B) as A and B are disjoint or mutually exclusive events.
Independent: Any two events are independent of each other if one has zero effect on the other i.e. the occurrence of one event doe not affect the occurrence of the other. If A and B are two independent events then, P(A∩B)=P(A)*P(B).
Sum rule: Sum rule states that
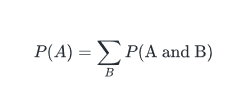
This is also known as marginal probability as it denotes the probability of event A by removing out the influence of other events that it is together defined with.
Example: If the probability that it rains on Monday is 0.3 and the probability that it rains on other days this week is 0.6, what is the probability that it will rain this week?
Solution: From the sum rule, P(rain) = P(rain and it is a Monday) + P(rain and it is not Monday). Hence the P(rain) = 0.7